
메인화면
시스템으로 구축하고자 하는 업무에 대해 Key, 속성, 관계 등을 정확하게 표현하고 재사용성이 높은 모델링으로 알맞은 것은?
엔터티의 특징으로 적절하지 않은 것은?
속성의 특징으로 적절하지 않은 것은?
식별자의 특징으로 적절하지 않은 것은?
식별자 관계에 대한 설명으로 적절하지 않은 것은?
함수 종속성에 대한 설명으로 적절한 것은? - 일반 속성이 주식별자 전체에 함수적으로 종속될 때, 제2정규형을 만족합니다. (예시) 상품번호에 상품명이 종속되어 있는 경우
아래의 경우 생성하는 식별자는? 업무적으로 만들어지지는 않지만 원조식별자가 복잡한 구성을 갖고 있기 때문에 인위적으로 만든 식별자
NULL에 대한 설명으로 적절한 것은?
CTAS 에 대한 설명으로 적절하지 않은 것은?
View 에 대한 설명으로 적절하지 않은 것은?
Database의 논리적 업무 최소 단위는?
아래의 계층형 쿼리와 결과에 대한 설명으로 적절하지 않은 것은? (조건: emp_no는 하위 사원 번호, mgr_no는 상위 관리자 번호를 나타냄) CONNECT BY Prior emp_no = mgr_no
SQL의 결과가 다른 것은? (조건: Oracle에 한함)

아래 SQL의 결과로 알맞은 것은? SELECT ..., COALESCE(A, 50 * B, '50')
제약 조건에 대한 설명으로 적절하지 않은 것은?
아래의 SQL과 같은 결과를 반환하는 SQL은? SELECT * FROM 테이블 A WHERE A.번호 IN (SELECT 번호 FROM 테이블 B WHERE A.성별 = B.성별);
아래의 Window Function 설명에 맞는 것은? 파티션별 윈도우의 전체 건수에서 현재 행보다 작거나 같은 건수에 대한 누적백분율을 구하는 함수
아래의 SQL 결과로 알맞은 것은? <sql> SELECT COUNT(*) FROM TABLE_B WHERE COL2 NOT IN (SELECT COL1 FROM TABLE_A); </sql>

아래의 SQL 결과로 알맞은 것은? SELECT * FROM TABLE_B WHERE COL2 IN ('A', 'B', NULL);

아래의 SQL 결과로 알맞은 것은? SELECT 나이_그룹, AVG(나이) AS 평균_나이 FROM 테이블명 GROUP BY 나이_그룹;

아래의 SQL 에서 7780 번의 결과는? SELECT EMPLOYEE_ID, ROW_NUMBER() OVER (ORDER BY SALARY) AS ROW_NUM, RANK() OVER (ORDER BY SALARY) AS RANK_NUM, DENSE_RANK() OVER (ORDER BY SALARY) AS DENSE_RANK_NUM FROM EMPLOYEES;

강좌번호가 100, 101인 과목을 동시에 듣는 학번을 구하는 SQL로 알맞은 것은?

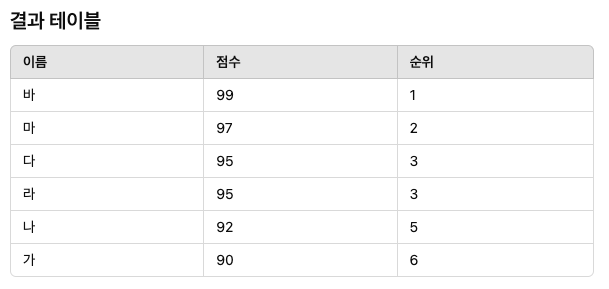
아래의 결과를 출력하는 SQL의 빈칸에 적절한 것은? WITH t1 AS ( SELECT * FROM ( SELECT '가' 이름, 90 점수 FROM dual UNION ALL SELECT '나' 이름, 92 점수 FROM dual UNION ALL SELECT '다' 이름, 95 점수 FROM dual UNION ALL SELECT '라' 이름, 95 점수 FROM dual UNION ALL SELECT '마' 이름, 97 점수 FROM dual UNION ALL SELECT '바' 이름, 99 점수 FROM dual ) ) SELECT 이름, 점수, (SELECT (1) FROM t1 t2 WHERE (2)) AS 순위 FROM t1 ORDER BY 순위;
아래의 빈칸에 알맞은 것은? 입력, 수정, 삭제한 데이터에 대해 전혀 문제가 없다고 판단됐을 경우 ( ) 명령어로 트랜잭션을 완료할 수 있다.
테이블의 데이터와 종속된 테이블을 지우는 명령어로 알맞은 것은?
오라클에서 행이 2건인 테이블에서 결과가 다른 SQL은?
아래 SQL에 대한 설명으로 알맞은 것은? (오라클 기준) create table emp_test as select * from hr.employees; UPDATE emp_test a SET salary = (SELECT salary * 1.1 FROM emp_test b WHERE a.employee_id = b.employee_id AND b.department_id = 60); SELECT * FROM emp_test WHERE department_id = 90;
아래 SQL의 결과로 알맞은 것은? SELECT COL1, SUM(매출) AS 총매출 FROM ... GROUP BY COL1 ORDER BY 총매출

아래의 SQL을 수행했을 때, 최종 결과는? (오라클 기준) CREATE TABLE 테이블명 ( COL1 NUMBER PRIMARY KEY, COL2 NUMBER CHECK (COL2 > 500) ); INSERT INTO 테이블명 (COL1, COL2) VALUES (1, 770); COMMIT; INSERT INTO 테이블명 (COL1, COL2) VALUES (1, 600); UPDATE 테이블명 SET COL2 = 400 WHERE COL1 = 1; SELECT SUM(COL2) FROM 테이블명;
아래의 SQL에 대한 설명으로 알맞은 것은? SELECT * FROM 고객테이블 WHERE COL1 LIKE 'A%';
아래 SQL의 결과로 알맞은 것은? SELECT COUNT(*) + COUNT(COL1) + COUNT(DISTINCT COL2) FROM 테이블명;

단일행 함수에 대한 설명으로 적절하지 않은 것은?
아래의 SQL 결과를 출력하는 SQL로 알맞은 것은?

Inner Join에 대한 설명 중 적절하지 않은 것은?
아래 SQL의 결과로 알맞은 것은? SELECT * FROM T1 INNER JOIN T2 ON T1.COL2 = T2.COL2 WHERE 1=1 AND T1.COL3 >= 3 AND T2.COL2 IN ('A', 'B');

서브쿼리에 대한 설명으로 적절하지 않은 것은?
아래 SQL에 대한 결과와 같은 것은? SELECT CASE WHEN COL1 = 'X' THEN NULL ELSE COL1 END AS 결과 FROM 테이블명;
다음 SQL 중 행의 수가 가장 많은 결과를 반환하는 것은?

아래의 설명을 만족하는 SQL로 알맞은 것은? 부서별로 연봉은 오름차순, 연봉이 100 ~ 200 사이인 연봉자 수 구하기
아래의 SQL 결과로 적절한 것은? SELECT * FROM T1 NATURAL JOIN T2;
